
Project Detail
Machine Learning Model Explorations for Classifying Music Genres.
Music plays a crucial role in people's lives, serving purposes such as relaxation, self-comfort, and emotional expression. Despite the accessibility of various music genres on streaming platforms, artists often release audio files without specifying genres, leading to reduced visibility and limited sharing opportunities. This project aims to efficiently classify audio resources into distinct music genres using various machine learning techniques. By improving genre classification, we can enhance music recommendations and support the music industry's development.
Machine Learning Engineer
5 months
New York, NY


Why Are We Doing This
Unlabeled music genres could limit the exposure of artists' work and affect music recommending algorithms. Properly classified genres not only enhance user experience on streaming platforms but also ensure that culturally and historically significant music is not under-publicized. This project seeks to fill this gap by developing a solution that accurately classifies music genres, thereby improving the overall user experience and promoting a richer diversity of music.
Dataset Overview
We utilized the GTZAN dataset, a widely-used resource for music genre classification. This dataset comprises:
10 Genres: Each with 100 audio files of 30 seconds each.
Mel Spectrograms: Visual representations of audio files, facilitating neural network classification.
CSV Files: Containing mean and variance of extracted features for both 30-second and 3-second audio segments.
The GTZAN dataset, collected from various sources like CDs and radio, provides a diverse range of recording conditions, making it ideal for robust classification model training.
How Might We Achieve It
To tackle this challenge, we explored three approaches:
1.
Supervised Learning with Manual Feature Engineering
Using the librosa library, we manually extracted features from music files and tested various supervised learning models, including LightGBM (L-GBM), which showed the highest accuracy.
2.
Deep Learning Without Feature Engineering
We implemented a Convolutional Neural Network (CNN) to process raw audio files, aiming to classify genres without manual feature extraction. However, this method yielded less reliable accuracy.
3.
Dimensionality Reduction Using Variational Autoencoder (VAE)
We experimented with VAE to generate feature vectors, hoping to improve classification accuracy. However, manual feature engineering with librosa outperformed VAE in our tests.
Data Visualizations - PCA Analysis
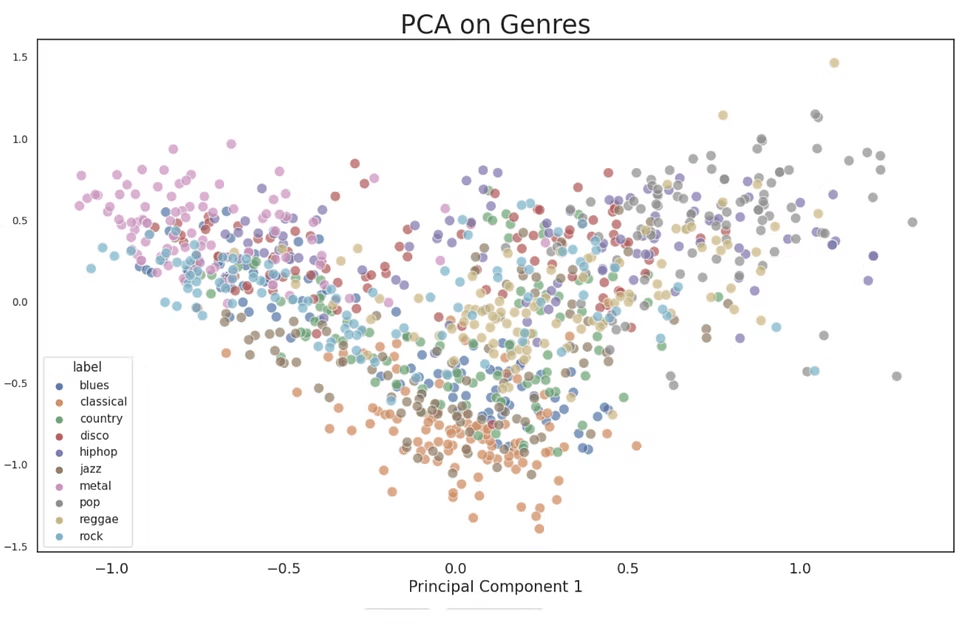
Manual Feature Engineering with Librosa
Demonstrated distinct genre clusters, indicating effective feature separation.

CNN Without Feature Engineering
Showed less distinct clustering, highlighting the challenges of automatic feature extraction.
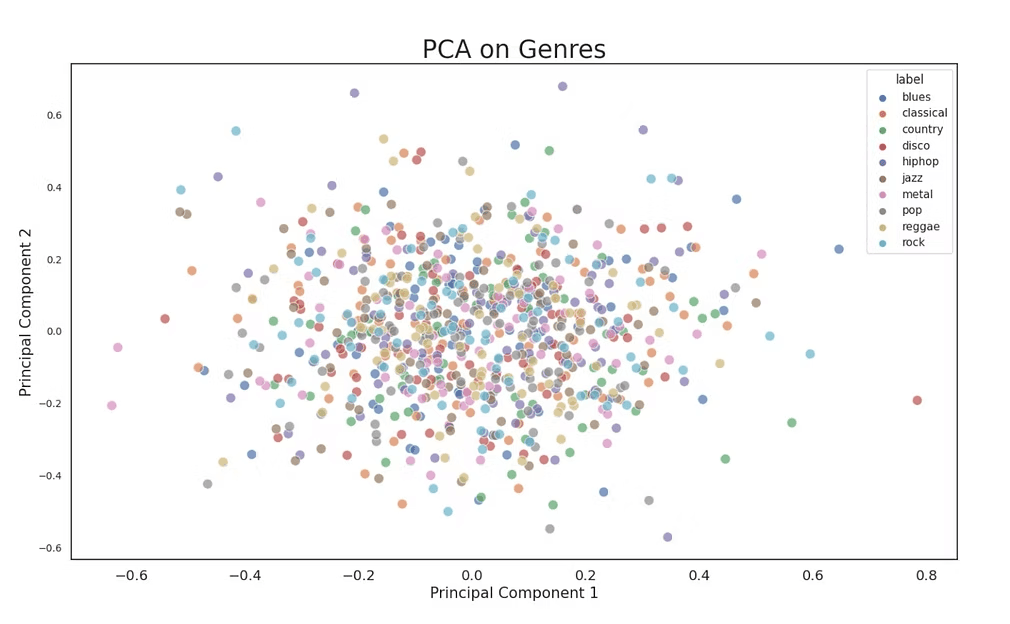
VAE Feature Engineering
Revealed poor clustering, suggesting VAE's limitations in extracting meaningful features for genre classification.
Data Visualizations - PCA Analysis
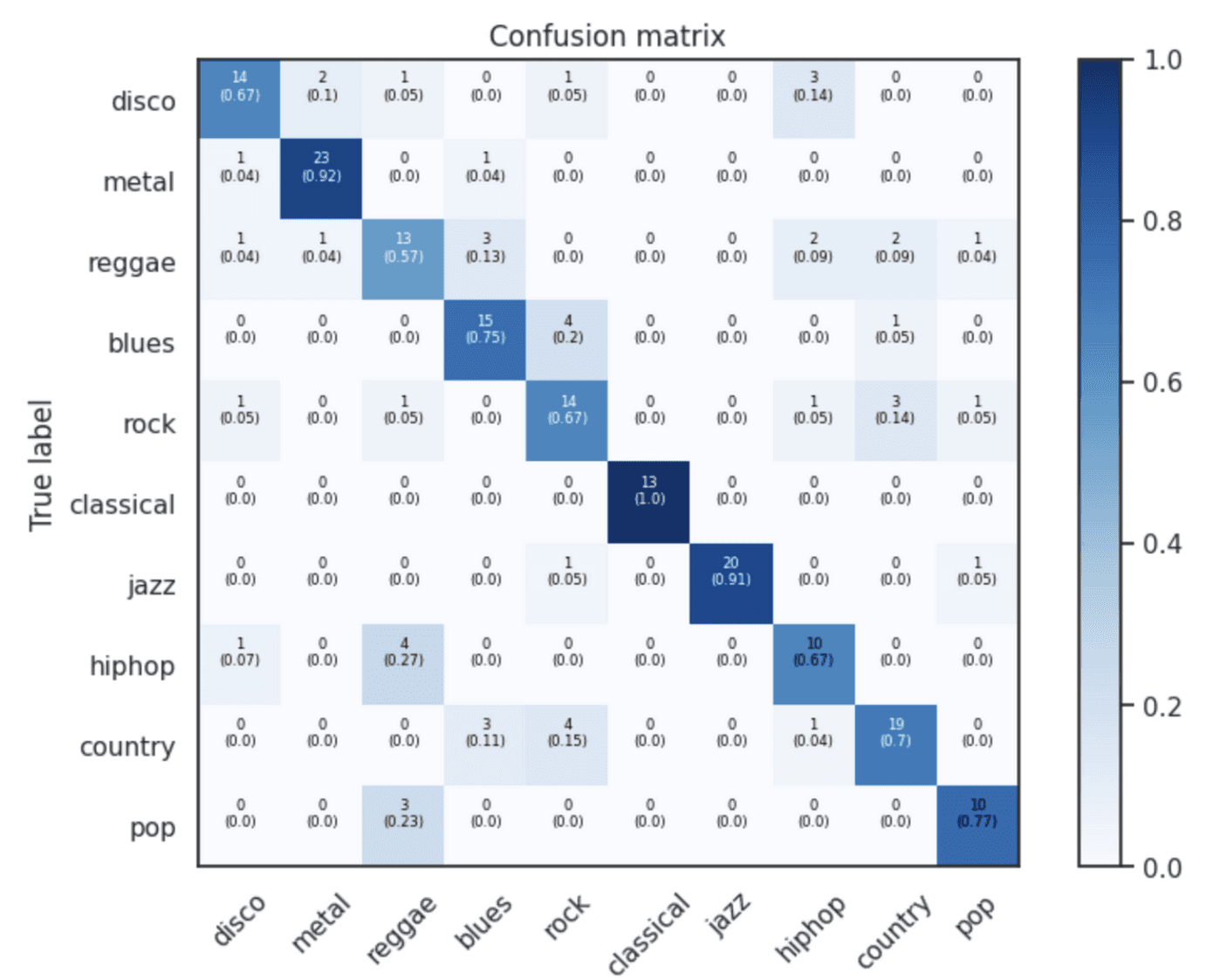
L-GBM with Librosa Features
Achieved the highest classification accuracy, as indicated by darker diagonal gradients in the confusion matrix.
CNN Without Feature Engineering
Showed weaker classification performance.
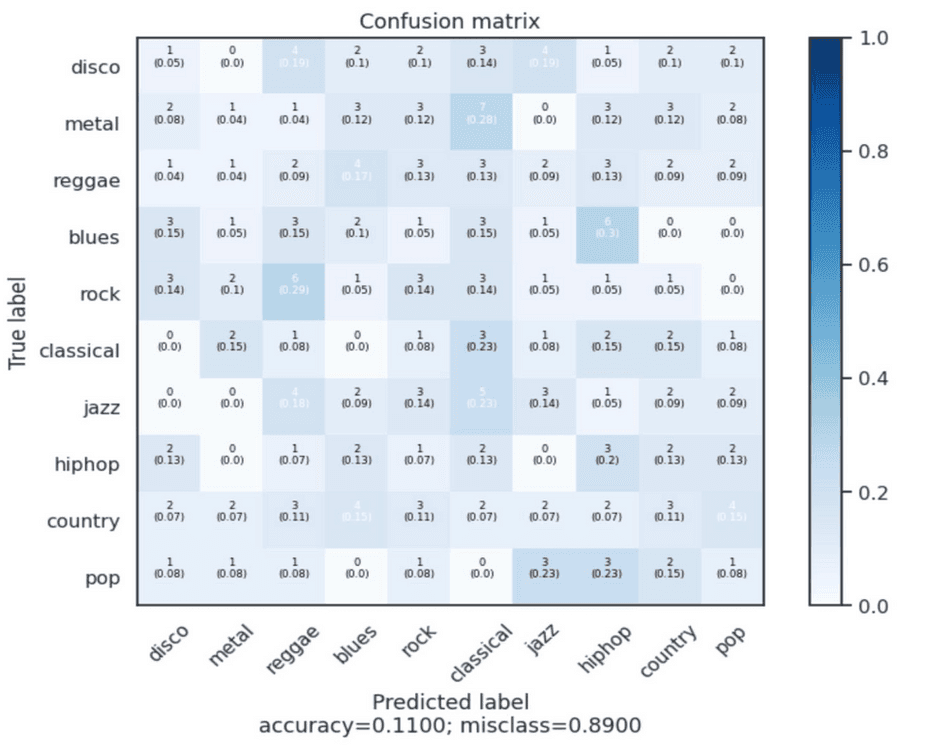
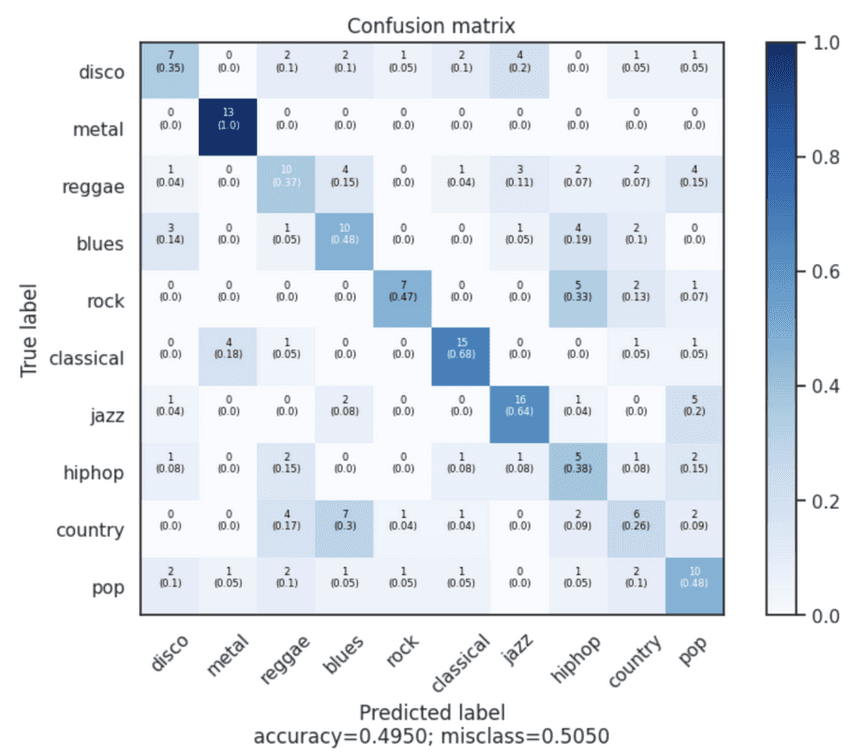
Logistic Regression with VAE Features
Displayed low accuracy and high misclassification rates, underscoring the need for better feature extraction methods.
Results Discussion
Our findings suggest that manual feature engineering using librosa significantly enhances classification accuracy, with L-GBM achieving the best performance. Deep learning models like CNN, while promising, require further optimization to match the effectiveness of manual feature extraction. The VAE approach did not perform well in our context, highlighting the importance of selecting appropriate feature extraction techniques.
Conclusion and Future Work
Our experiments confirm that L-GBM with librosa feature engineering provides the most accurate music genre classification. Future work could explore other deep learning algorithms, such as Convolutional Recurrent Neural Networks (CRNN) or Attention-based models, to potentially improve classification performance without extensive manual feature engineering.
Additionally, we discovered the Google What-If Tool (WIT) post-project completion. WIT could be a valuable asset for future iterations, allowing us to:
Test Performance in Hypothetical Situations: Simulate different scenarios to assess model performance under various conditions.
Analyze Feature Importance: Understand which features are most influential in the classification process.
Visualize Model Behavior: Compare the behavior of different models and subsets of input data, gaining insights into model performance and fairness metrics.
Incorporating WIT in future projects enables us to make more informed adjustments, improving classification accuracy and ensuring responsible AI deployment.
rh692@cornell.edu
©Gloria Hu 2025